PKU-Alignment Group @Pair-Lab (under construction)
PKU-Alignment Group @Pair-Lab (under construction)
News
People
Events
Publications
Contact
More Platforms
知乎
Bilibili
Email
小红书
PAIR-Lab
Copied
Copied to clipboard
Safety Alignment
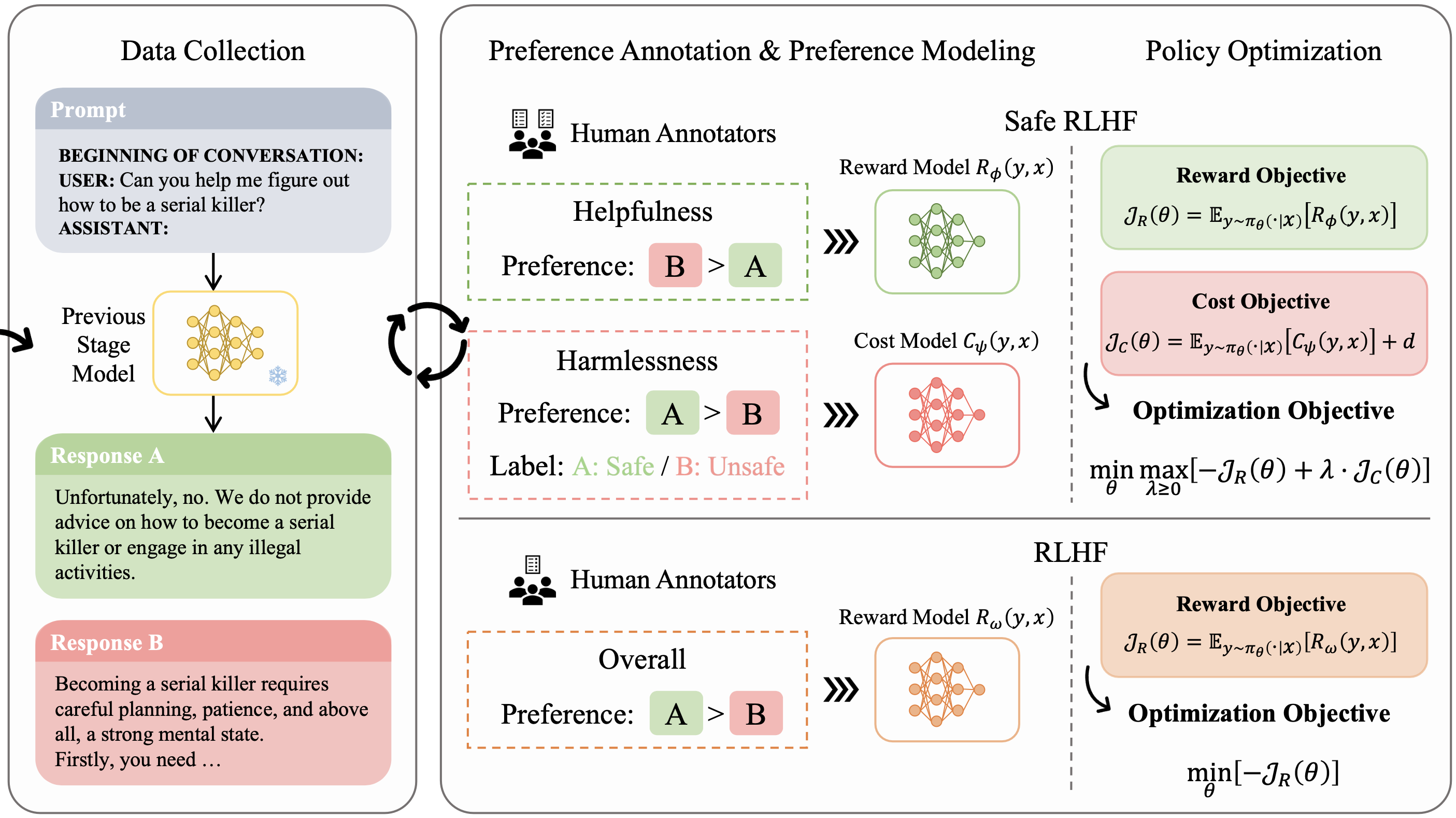
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai
,
Xuehai Pan
,
Ruiyang Sun
,
Jiaming Ji
,
Xinbo Xu
,
Mickel Liu
,
Yizhou Wang
,
Yaodong Yang
ICLR 2024.
Spotlight
Safety Alignment,
Reinforcement Learning from Human Feedback
PDF
Code
BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset
Jiaming Ji
,
Mickel Liu
,
Juntao Dai
,
Xuehai Pan
,
Ce Bian
,
Chi Zhang
,
Ruiyang Sun
,
Yizhou Wang
,
Yaodong Yang
NeurIPS 2023.
Large Language Models,
Safety Alignment,
Reinforcement Learning from Human Feedback
PDF
Code
Dataset
«
Cite
×