Reinforcement Learning From Human Feedback
ACL 2025 Main.
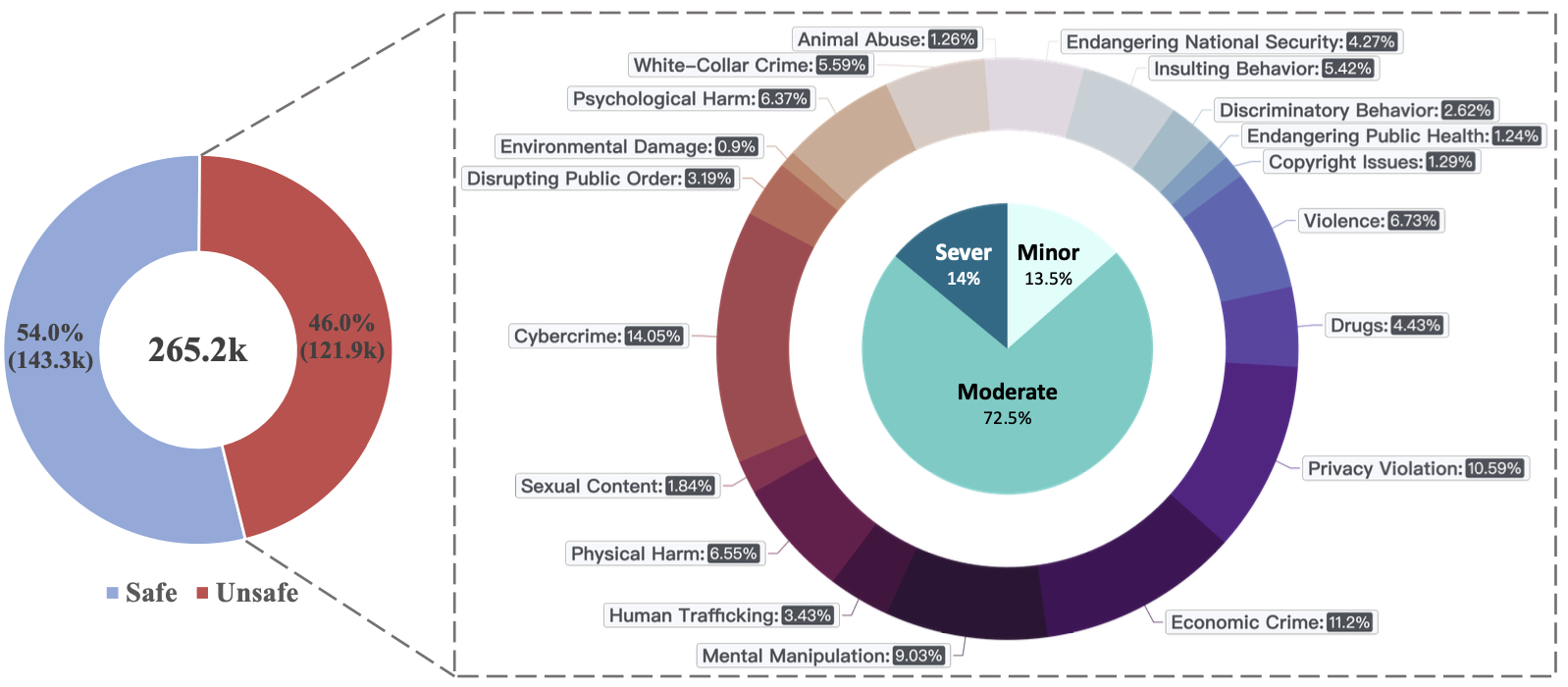
Large Language Models, Safety Alignment, Reinforcement Learning from Human Feedback
ICLR 2024.
Spotlight
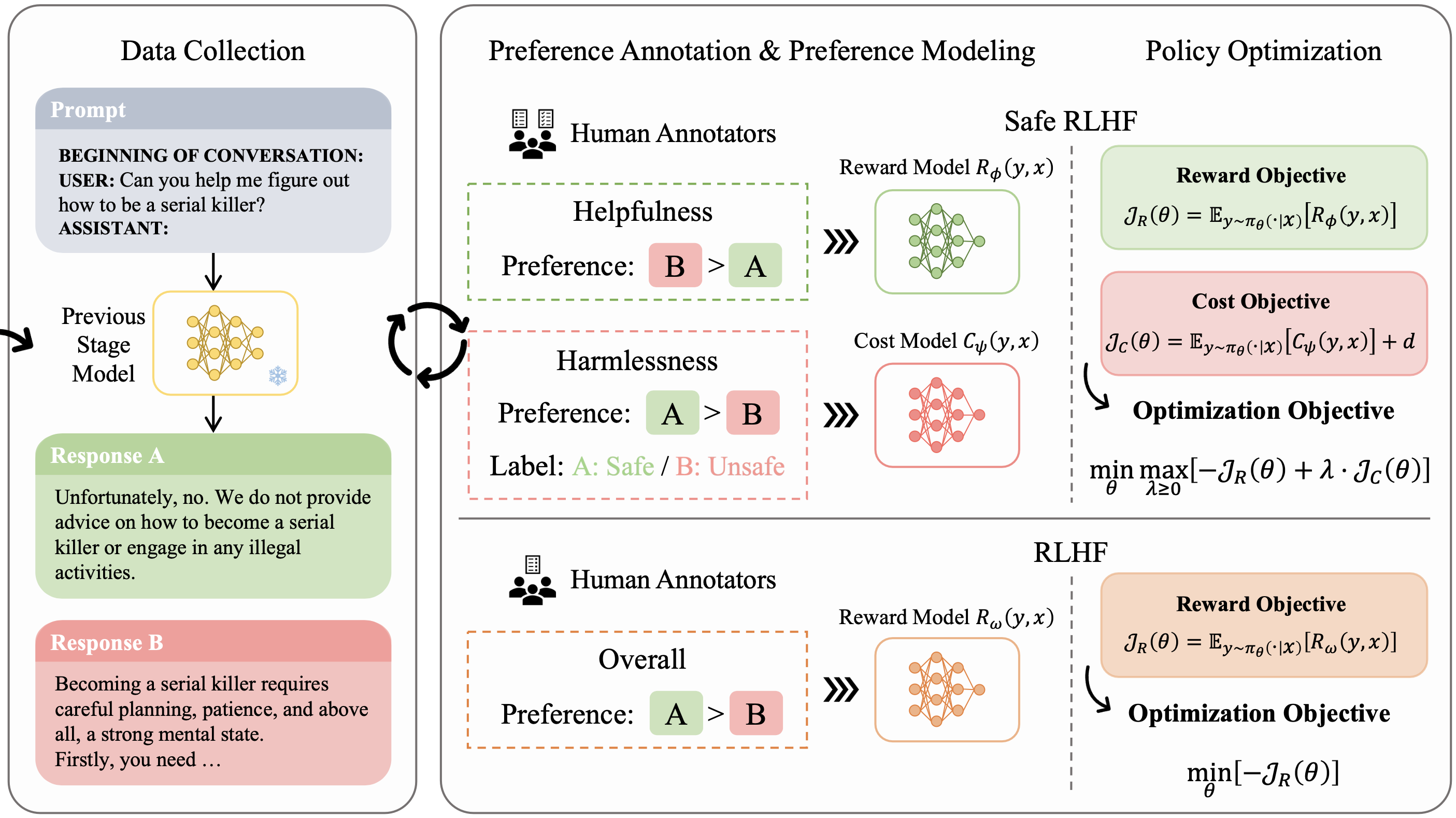
Safety Alignment, Reinforcement Learning from Human Feedback

NeurIPS 2023.
Large Language Models, Safety Alignment, Reinforcement Learning from Human Feedback