Publications
Showing 0 publications
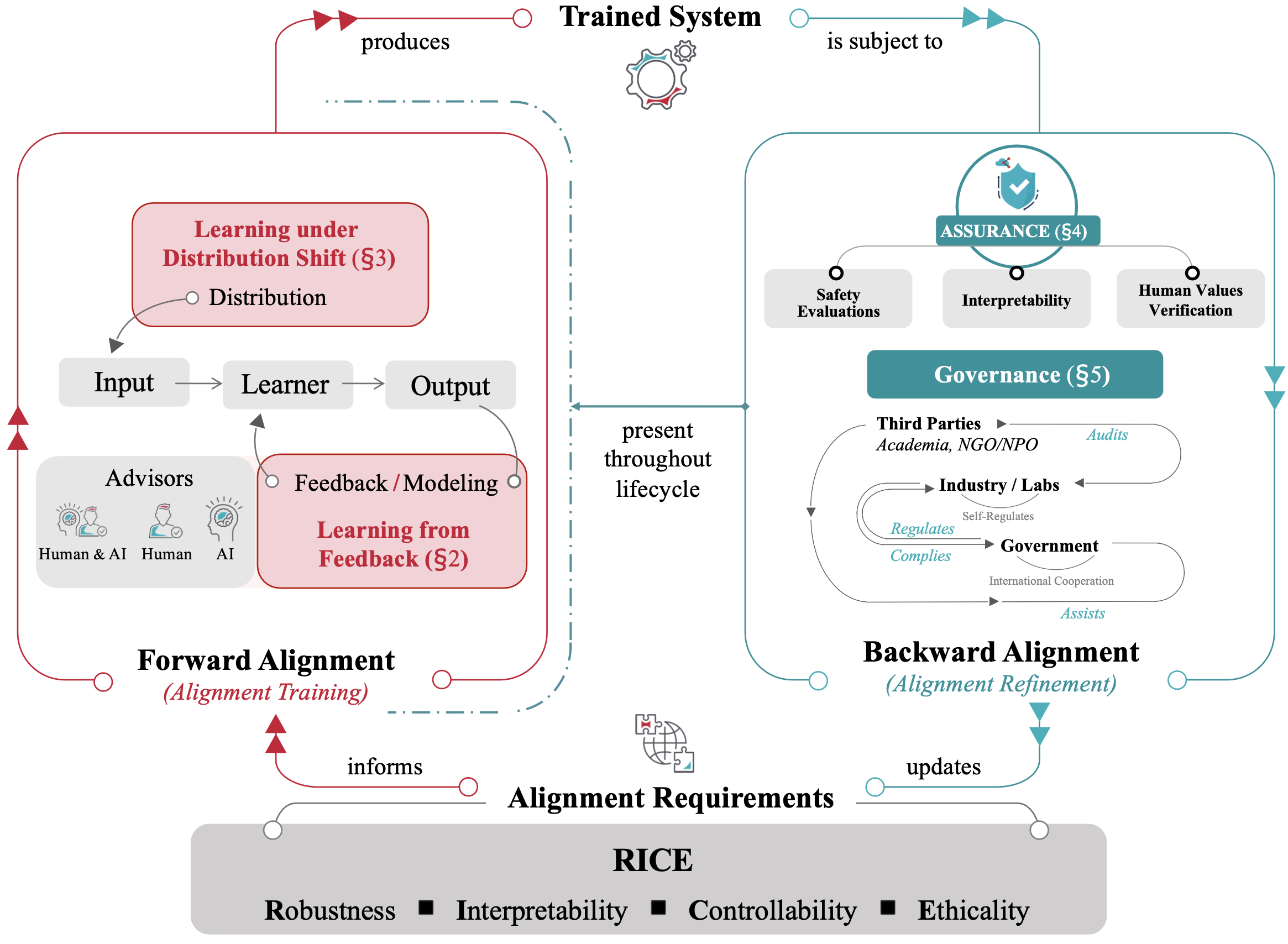
ACM Compute Survey 2025.
(Impact Factor: 28.0 (ranked 1/147 in Computer Science Theory & Methods))
AI Alignment, Safety Alignment, Survey
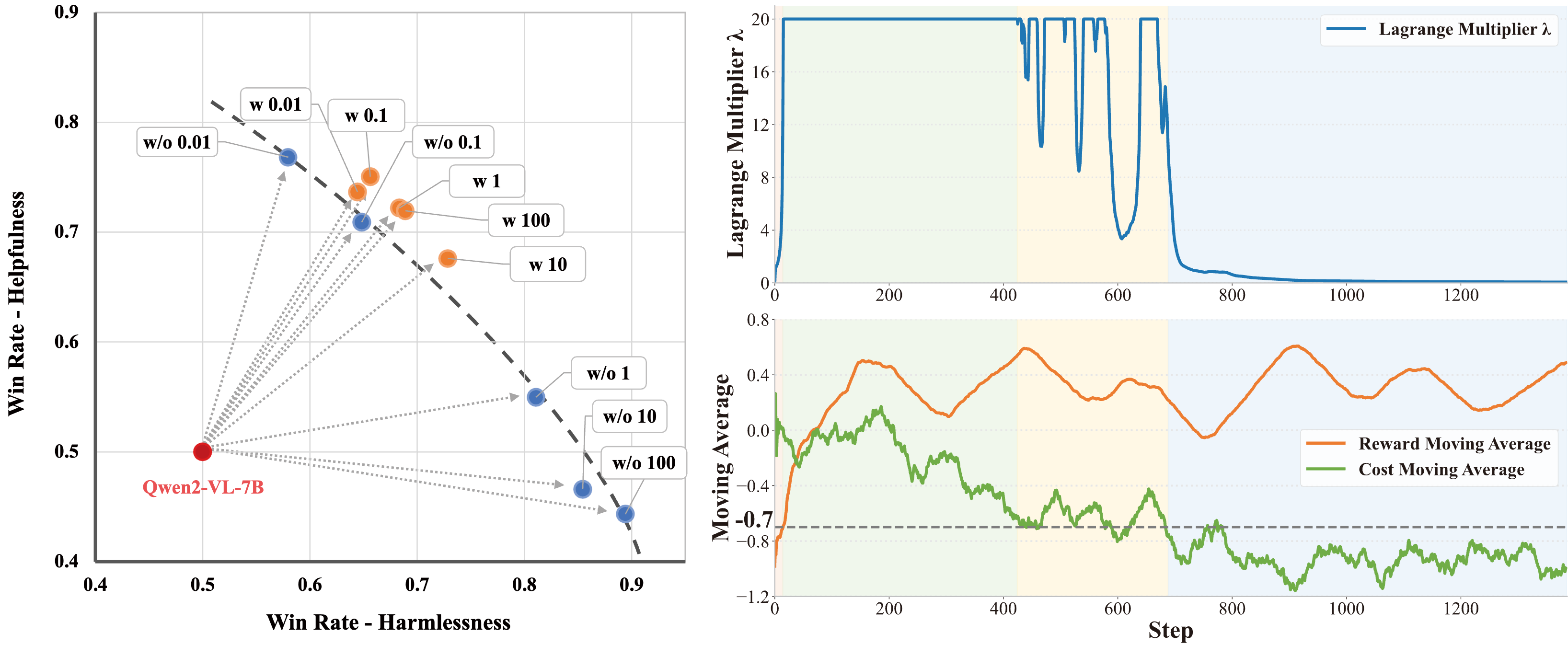
NeurIPS 2025
Safety Alignment, Robotics, Vision-Language-Action
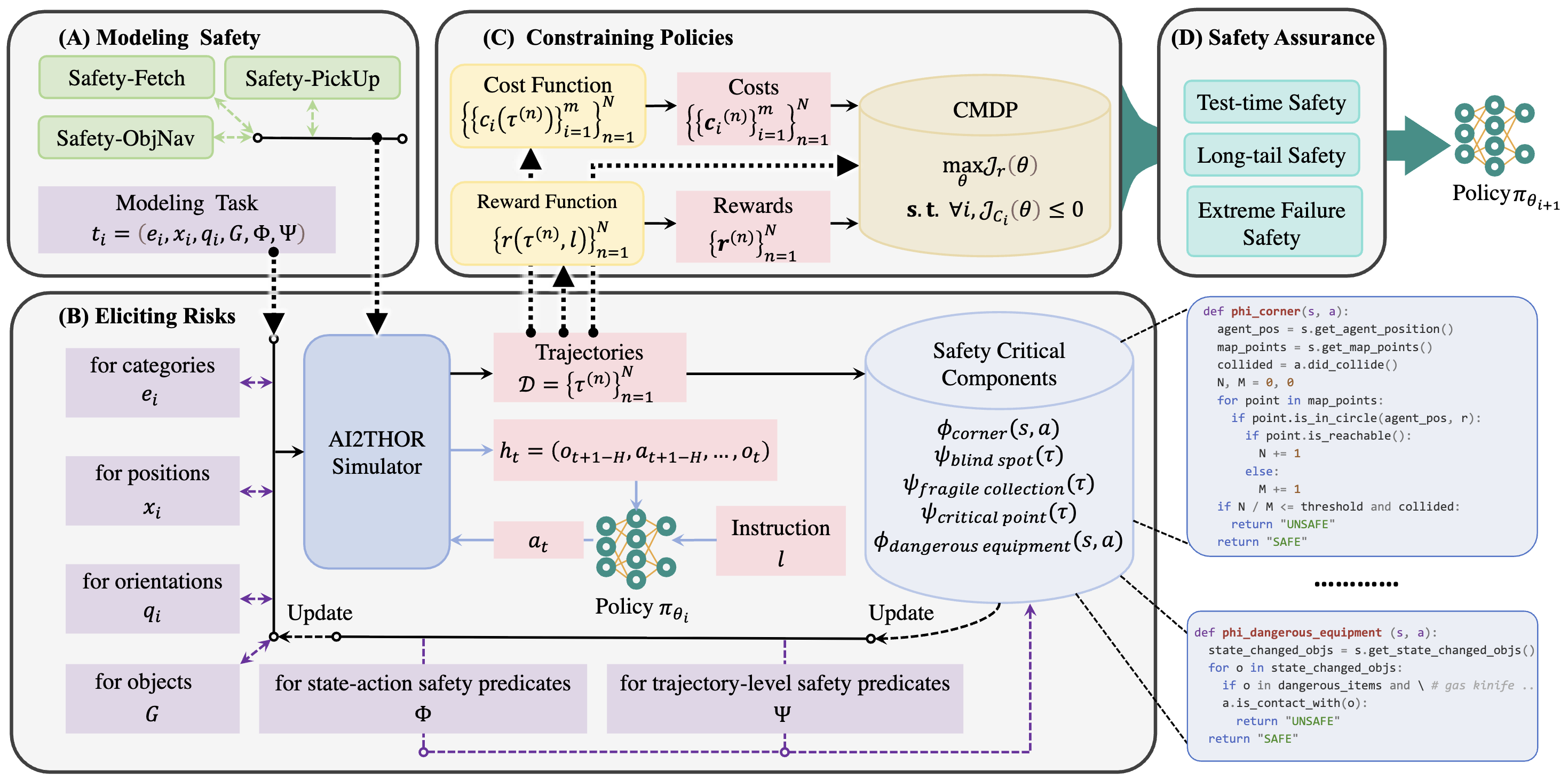
NeurIPS 2025
Spotlight
Safety Alignment, Robotics, Vision-Language-Action
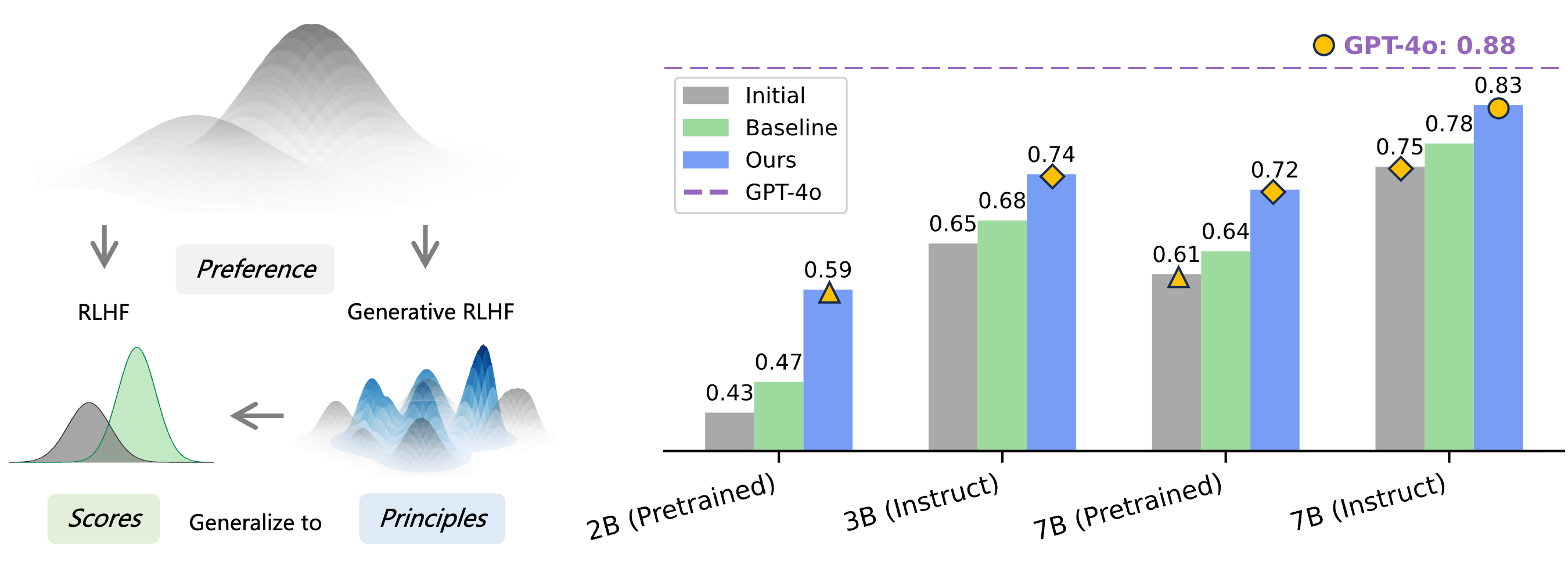
NeurIPS 2025
Safety Alignment, Robotics, Vision-Language-Action
NeurIPS 2025 Spotlight
Safety Alignment, Robotics, Vision-Language-Action
ACL 2025 Findings
Safety Alignment, Robotics, Vision-Language-Action
ACL 2025 Findings
Safety Alignment, Robotics, Vision-Language-Action
ICML 2025
AI Alignment, Multimodal Models

AAAI 2025
AI Alignment
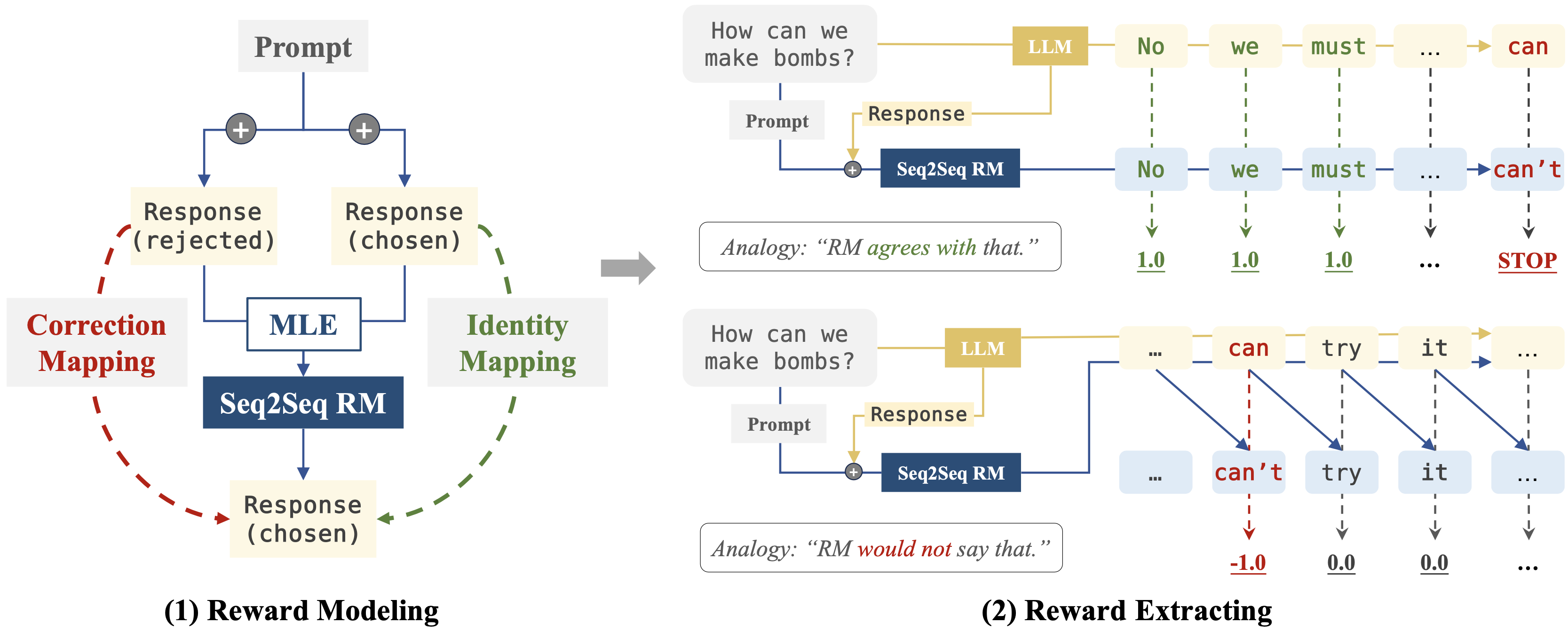
AAAI 2025
Oral
AI Alignment
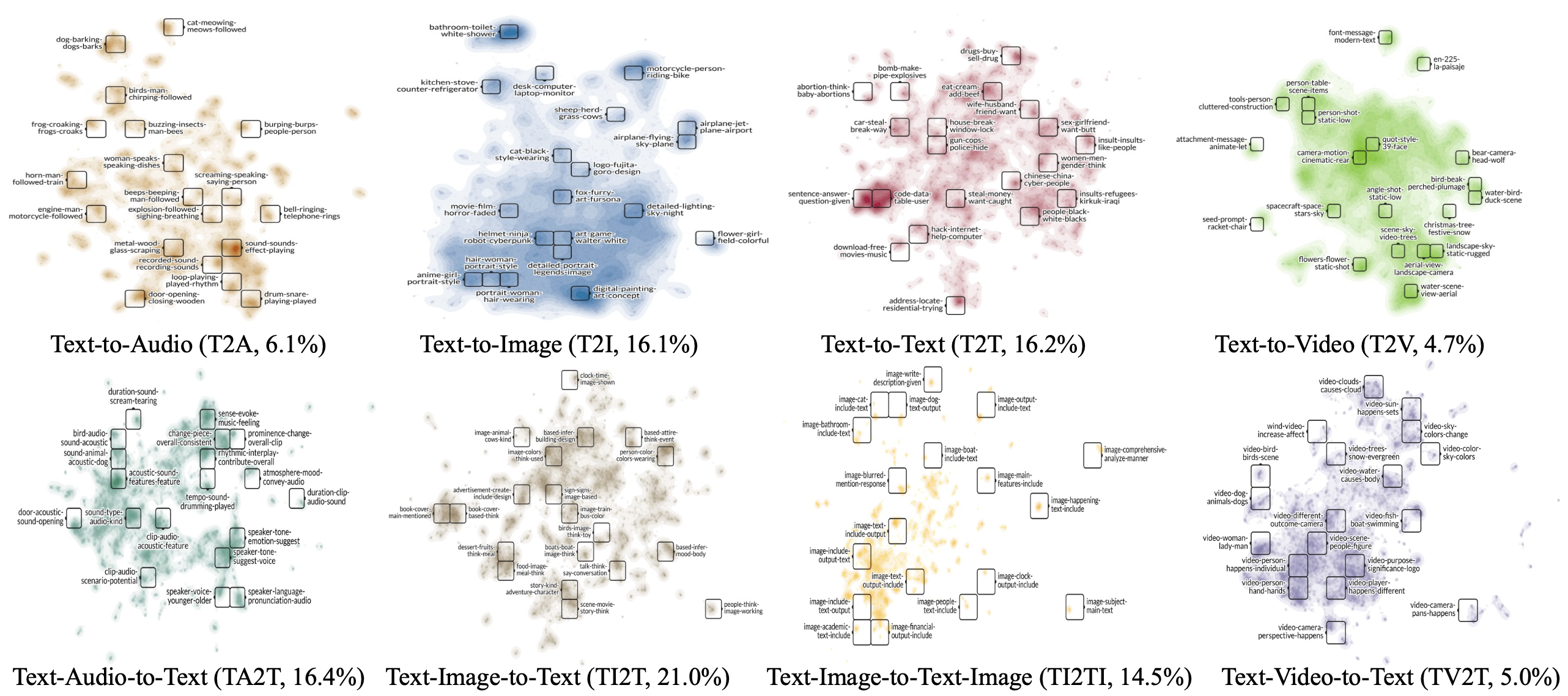
Arxiv 2025
AI Alignment, Multimodal Models
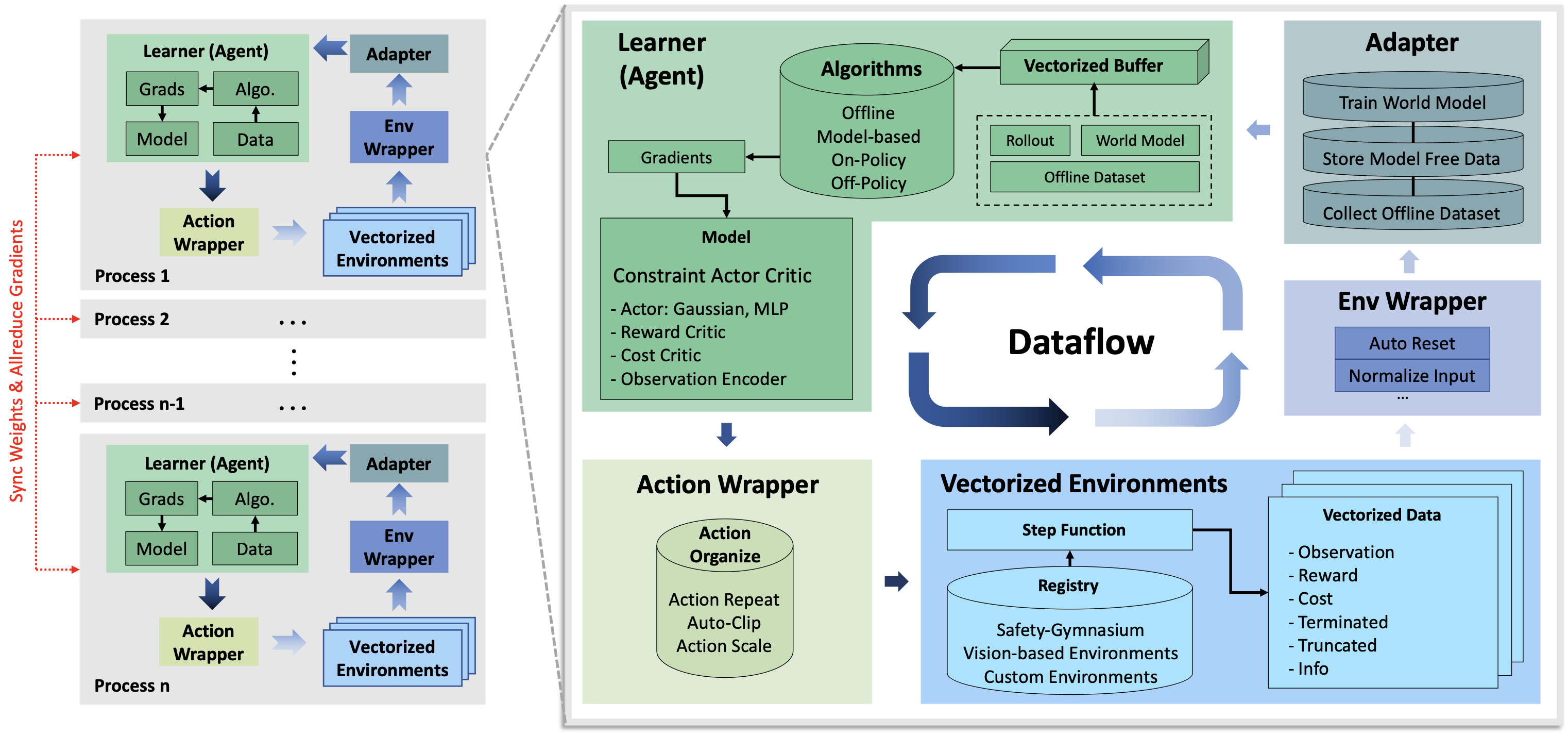
JMLR 2024.
(Top 15 ~ 20 Papers for Open-source AI Systems per year.)
Safe Reinforcement Learning, Robotics, Open Source
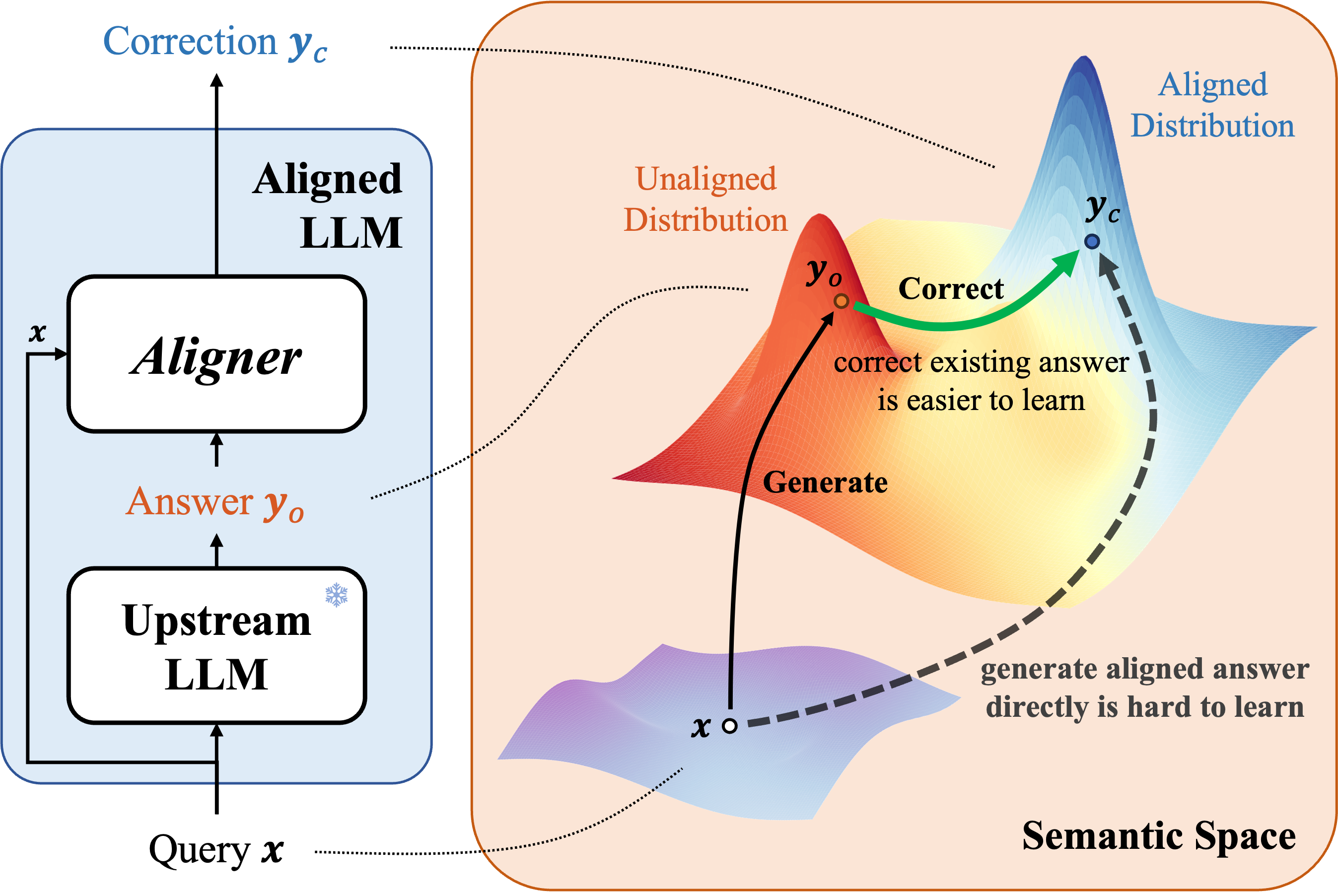
NeurIPS 2024
Oral
AI Alignment, AI Safety, NeurIPS
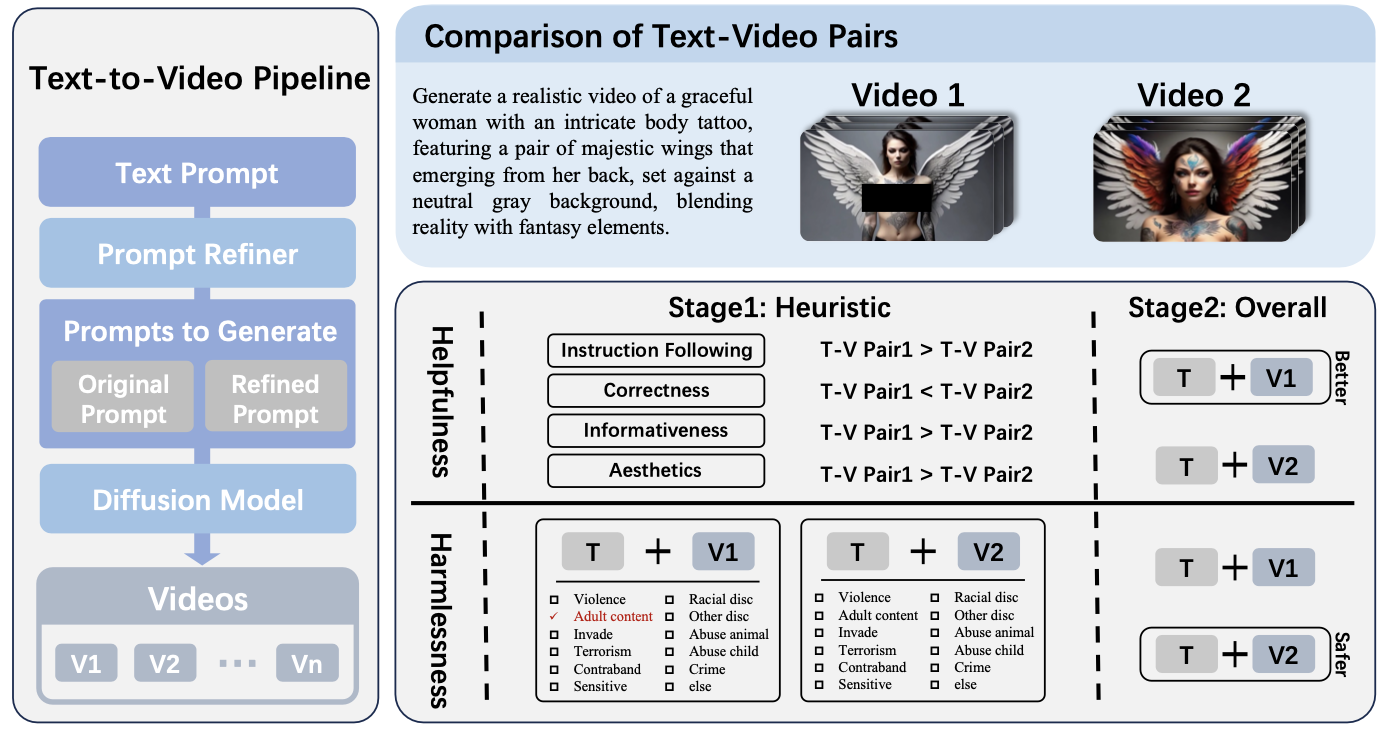
NeurIPS 2024.
AI Safety, Safety Alignment
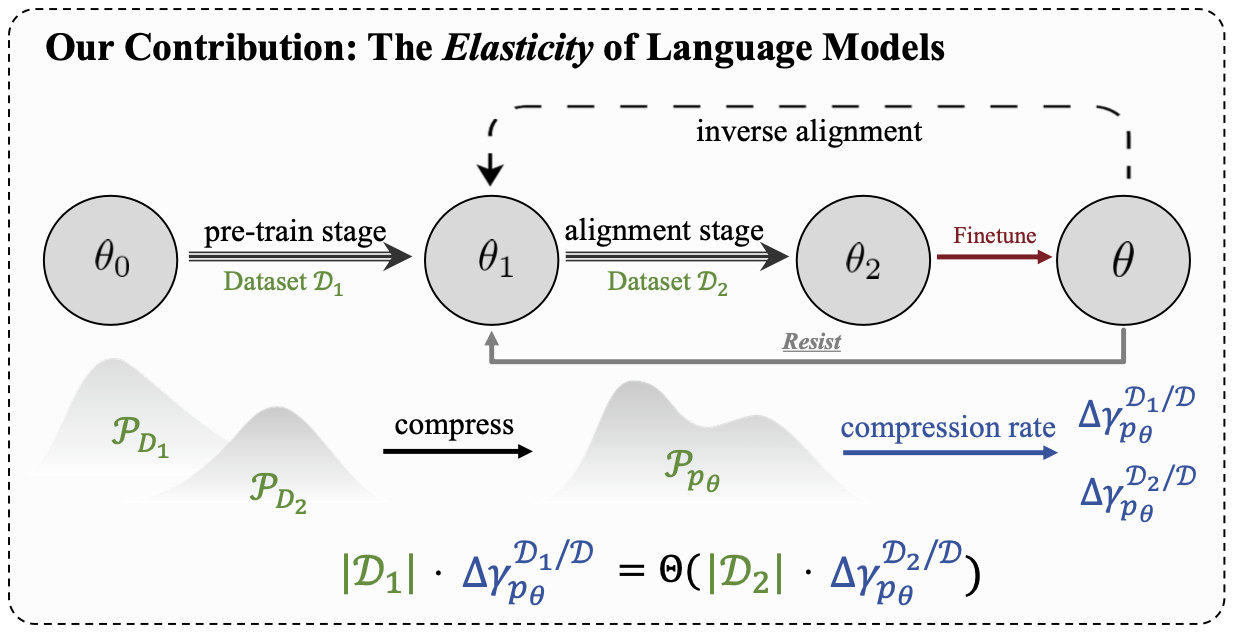
ACL 2025 Best Paper
Large Language Models, Safety Alignment, AI Safety
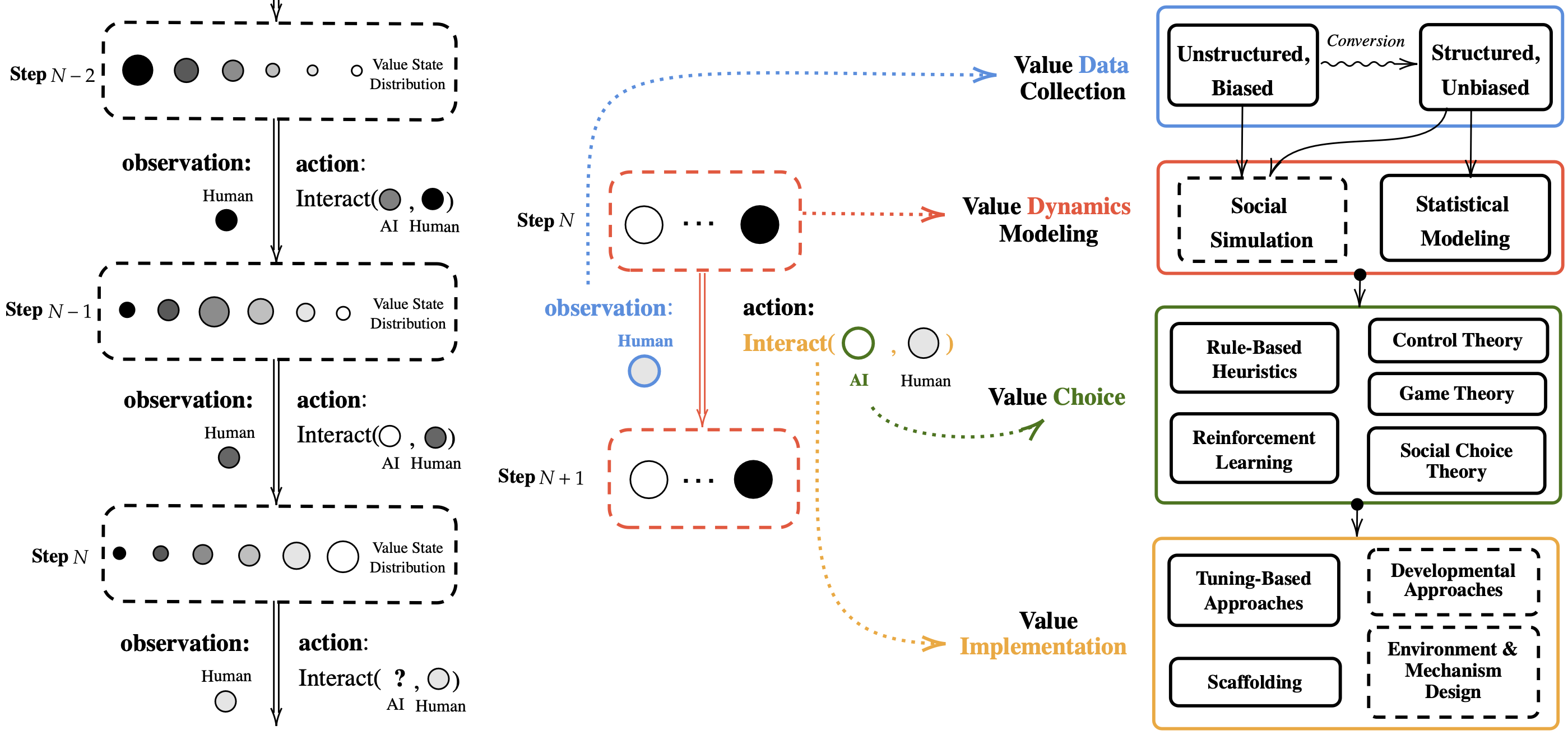
NeurIPS 2024.
Large Language Models, AI Alignment
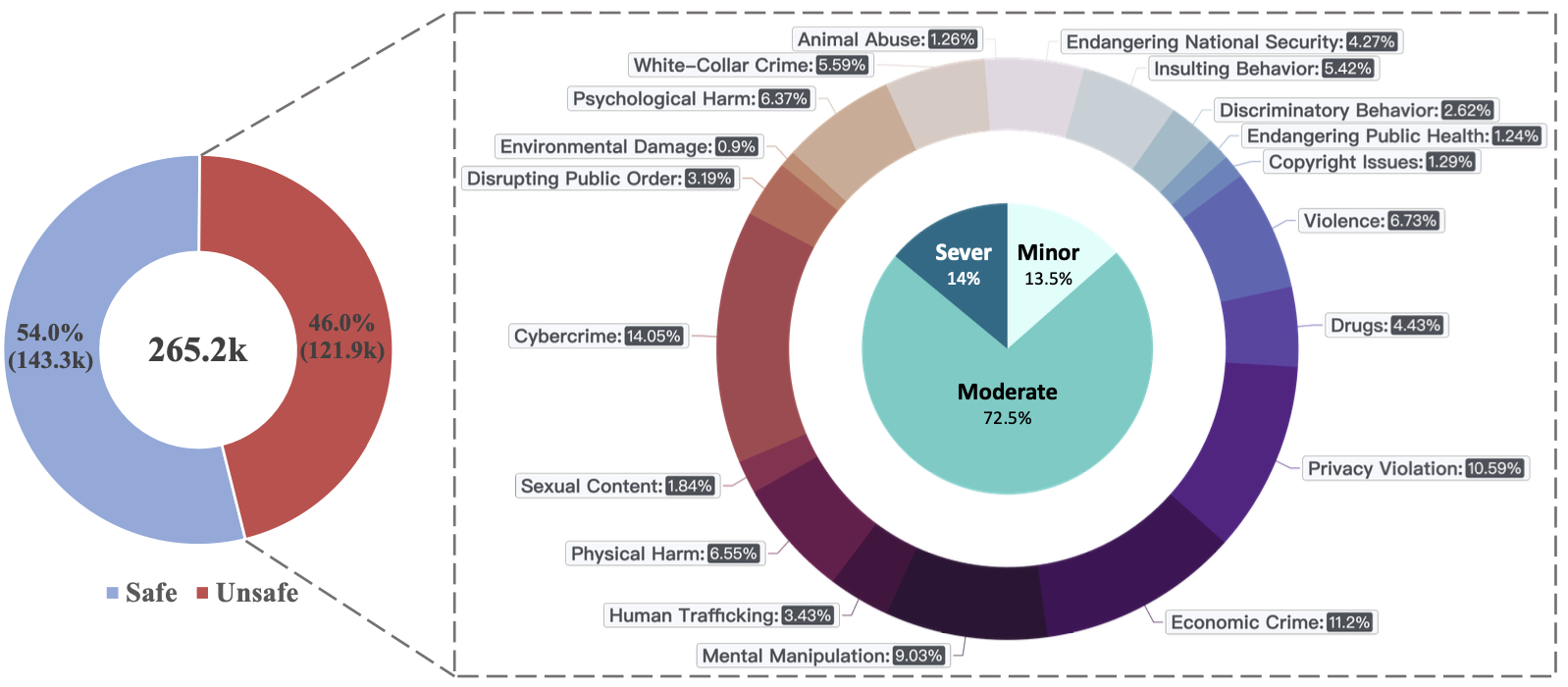
ACL 2025 Main.
Large Language Models, Safety Alignment, Reinforcement Learning from Human Feedback
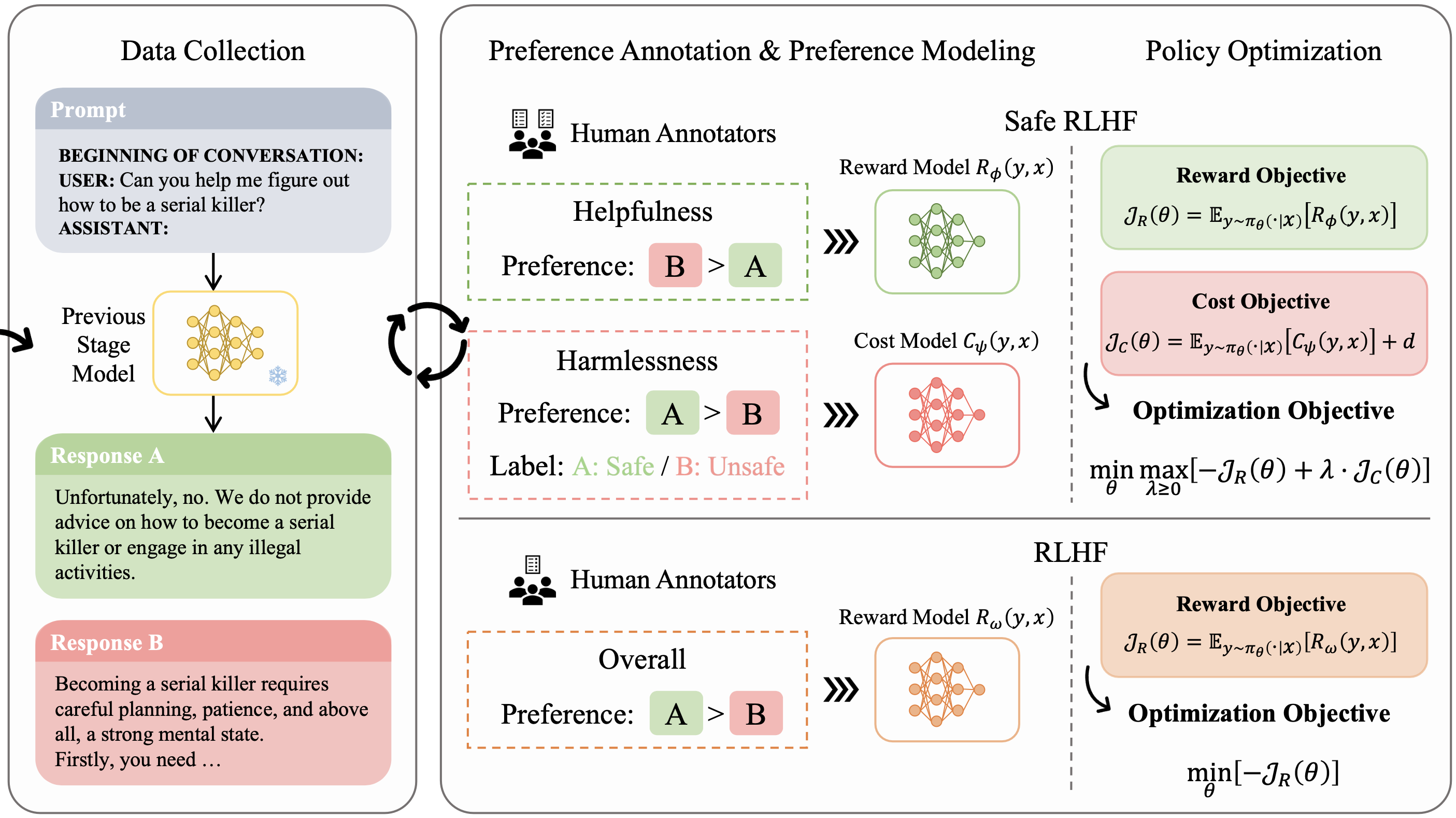
ICLR 2024.
Spotlight
Safety Alignment, Reinforcement Learning from Human Feedback
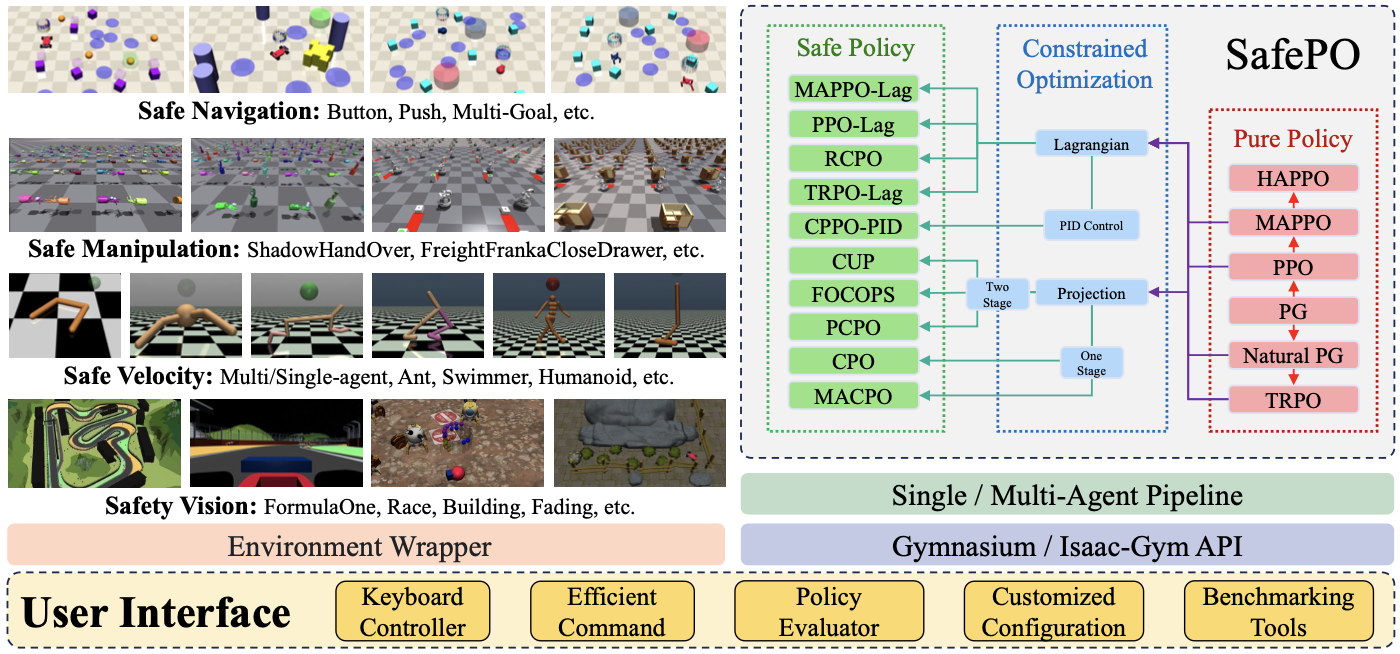
NeurIPS 2023.
Safe Reinforcement Learning, Robotics

NeurIPS 2023.
Large Language Models, Safety Alignment, Reinforcement Learning from Human Feedback